Comparing CNNs VS Vision Transformers for Medical Image Segmentation
A deep learning application that automatically segments the liver from 3D CT scans, comparing two architectures:
SwinUNETR (Vision Transformer) - State-of-the-art attention-based model
UNet (CNN) - Traditional convolutional baseline
Both models learn to recognize the liver through supervised learning:
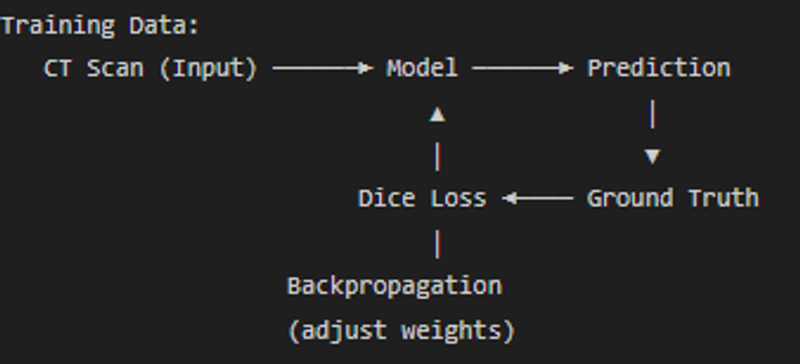
After seeing thousands of CT scans with manually labeled liver masks, the models learn:
- What intensity values correspond to liver tissue (~40-60 HU)
- What shape/position the liver occupies (upper right abdomen)
- What boundaries separate liver from surrounding organs
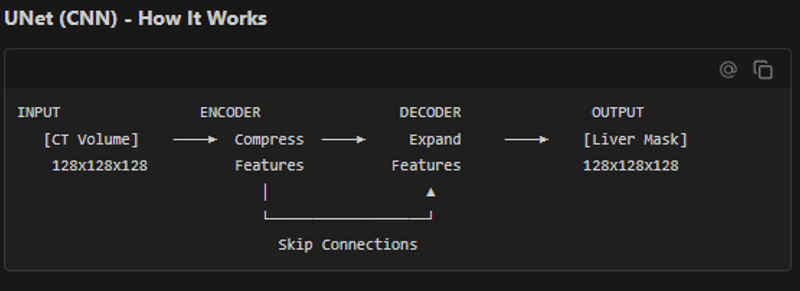
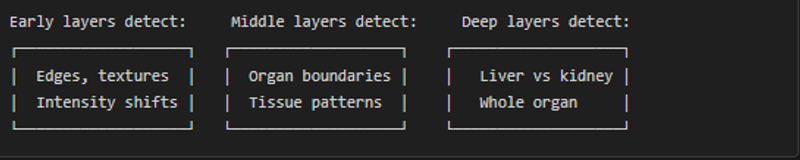
Convolution kernels (3x3x3 filters) slide across the image detecting patterns:
Limitation: Local Vision
Each convolution only sees a small local window
SwinUNETR (Vision Transformer) - How It Works

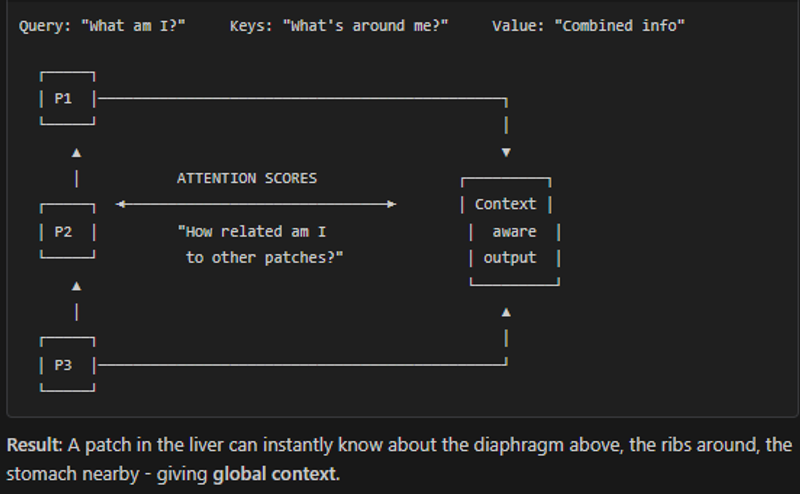
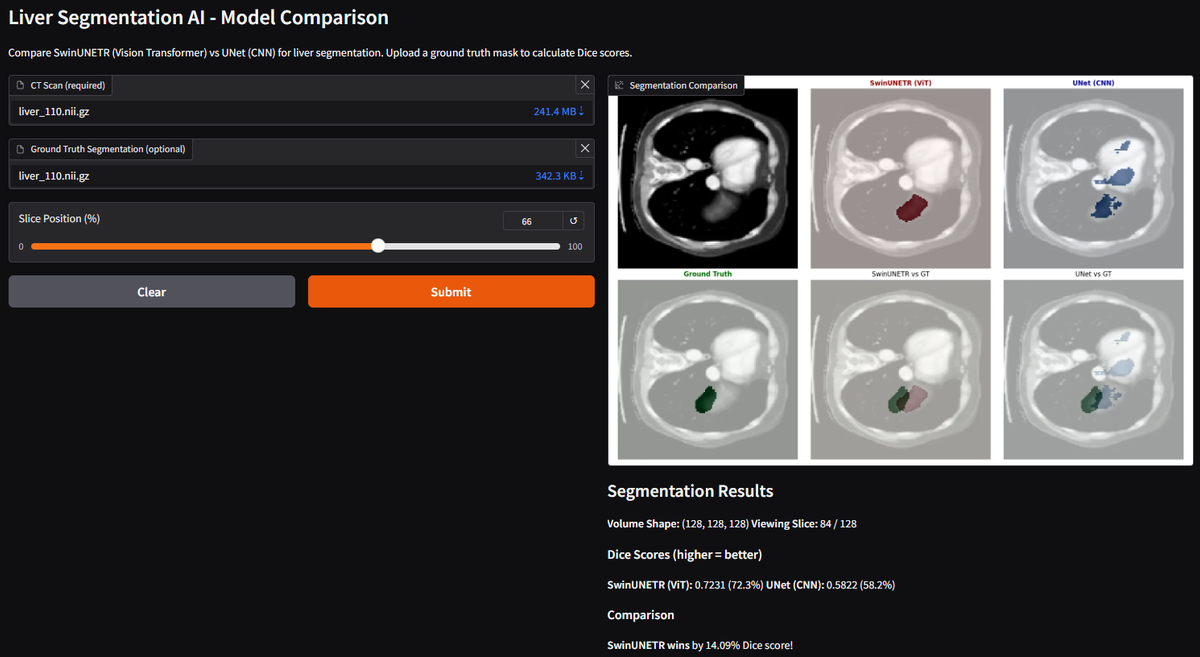
SwinTransformer does perform better but that comes with a price- More memory usage, more training time.
The model essentially asks at every voxel:
- What is the intensity here? (liver is ~40-60 HU)
- What textures surround this point? (liver is smooth)
- Where in the abdomen is this? (liver is upper right)
- What organs are nearby? (diaphragm above, kidney below)
All these factors combine into a probability score for each voxel being liver or not.